
The cult of tokenmaxxing
Big AI wants you to spend more on tokens but can't back up why

Last month The Information exposed Meta’s “Claudeonomics” leaderboard. It showed that a top employee averaged 281 billion tokens per month (~$1.4million in API costs). To compare, Alfred, which is running as my personal chief of staff averages around 2-4 billion tokens per month.
This happened just a few weeks after Jensen Huang’s famous quote where he declared that engineering output is basically a function of token budget. He said:
“If that $500,000 engineer did not consume at least $250,000 worth of tokens, I am going to be deeply alarmed. Every engineer is going to have a token budget. It is now one of the recruiting tools in Silicon Valley: how many tokens come along with my job?”
But he’s not alone. Since Claude Code was launched nearly a year ago, every player in Big AI seems to be in agreement that you should spend more money on tokens.
Boris Cherny, the creator of Claude Code said a year ago:
“Don't try to cost-cut at the beginning. Start by giving engineers as many tokens as possible. It's an ROI question. It's not a cost question.”
Just a few days ago Marc Benioff bragged about his Anthropic bill on a podcast:
“These coding agents are awesome. Anthropic is awesome. I am going to probably use $300 million of Anthropic this year at Salesforce. Coding. Everything's going to be cheaper to make.”
Before Christmas, OpenAI started giving out plaque’s akin to YouTube’s but for those who spend more money on tokens.

So it would seem we have entered the era of tokenmaxxing. Spend as much on tokens as possible because if you don’t you will be left behind in the permanent underclass that has been 18 months away for the last 3 years.


Corporations trying to make it cool to give them money is nothing new or sinister. It’s just called marketing. It’s the nerdy version of Coca Cola trying to convince you that there is no Christmas without their sweet black “diabetes in a can”.
The stakes are higher a bit though, because Coca Cola tries to equate with family and fun, whilst our favorite Big AI influencer bros are trying to convince you that we’re on the brink of “intelligence too cheap to meter” that will cHaNgE eVeRyThInG.
Please keep thinking about the time when intelligence is free so you don’t notice that we give awards for spending more on it.
That kind of intelligence is being metered, on a P&L.
This dichotomy has been bothering me for a while, so I’ll try to dissect this. Let’s look at the argument for “intelligence getting cheaper” and then let’s see what the data actually says.
LLMflation, and what came after
In November 2024, Andreessen Horowitz’s Guido Appenzeller coined “LLMflation” to describe a striking observation: between November 2021 and the time of writing, the cost of LLM inference for a given capability (say, MMLU 42) had dropped by a factor of 1,000. From $60 per million tokens (GPT-3 davinci) to $0.06 per million (Llama 3.2 3B on Together.ai).
The headline was that for equivalent performance, the cost falls 10× every year.
Epoch AI’s March 2025 study refined the picture. They found prices declining “between 9× per year and 900× per year, with a median of 50× per year.”
Faster than a16z’s headline, but with enormous variance across task types.
Is it true? Yes, but.
The curve holds for back-catalog quality. At the frontier, something else is happening. In April 2026, OpenAI launched GPT-5.5 at $5 input / $30 output per million tokens; a 2× hike over GPT-5.4 just seven weeks earlier. Anthropic shipped Opus 4.7 at the same $5/$25 as 4.5 but with a new tokenizer that consumes up to 35% more tokens for the same text. Smooth little bastards.
The decade-long “AI gets cheaper” thesis is intact when you only look at model costs. For the frontier (the place tokenmaxxers actually live) the curve has flattened and, in patches, reversed.
Instead of looking at specific models, let’s look at the “frontier model at the time” price. Notice that OpenAI is slowly raising their frontier pricing while everything else is relatively the same. Makes sense if we are to believe the reports of Altman treating their P&L as a permanent Burning Man.
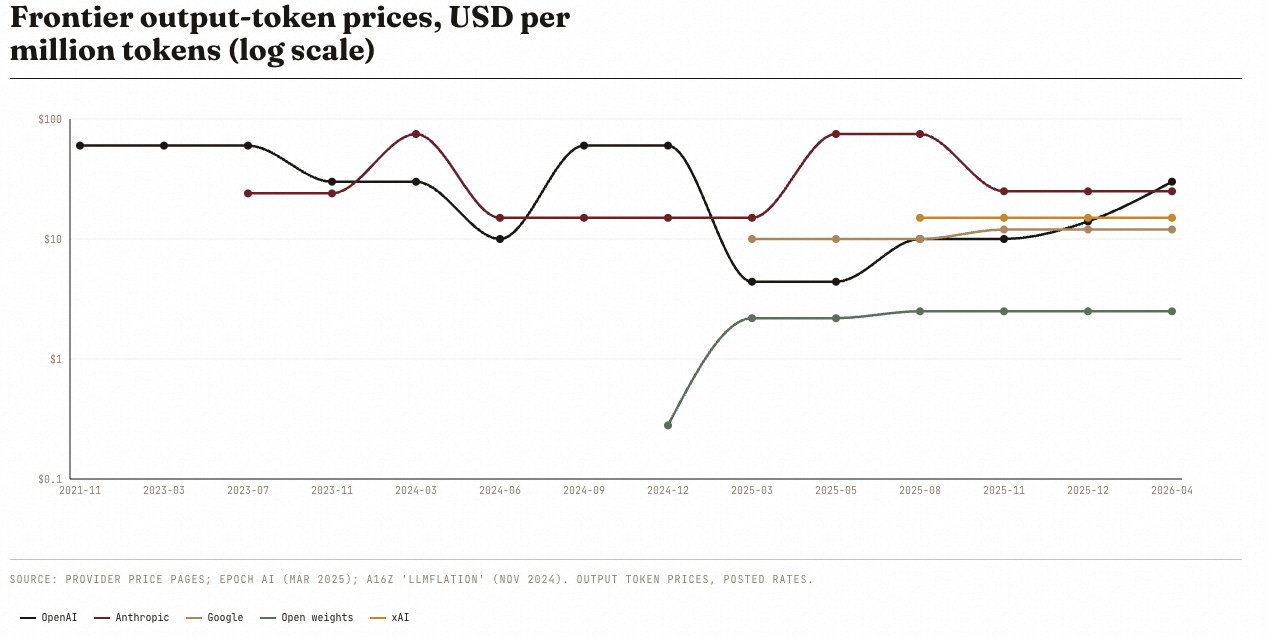
But hey, that’s fine, because these models are getting better so intelligence is getting cheaper, right? Older models are getting cheaper anyway, so what’s the problem?
The problem is twofold: the cost of intelligence and token demand.
Cost per unit of intelligence
The cleanest single metric for the “AI is getting cheaper” thesis: take a model’s posted output price ($ per million tokens), divide by a synthetic Intelligence Index (a normalized 0–100 composite of MMLU-Pro, GPQA Diamond, and SWE-Bench Verified).
Lower ratio = better deal.
Plot every notable model released between November 2022 and April 2026.
The dashed oxblood line is the frontier,the running minimum, the all-time cheapest deal seen so far. Two sharp drops dominate it: GPT-3.5 in March 2023 (a 70× improvement over GPT-3 in twelve weeks) and DeepSeek V3 in December 2024 (an order of magnitude below anything before, and still the absolute floor sixteen months later). Every flagship released since lives above that floor.
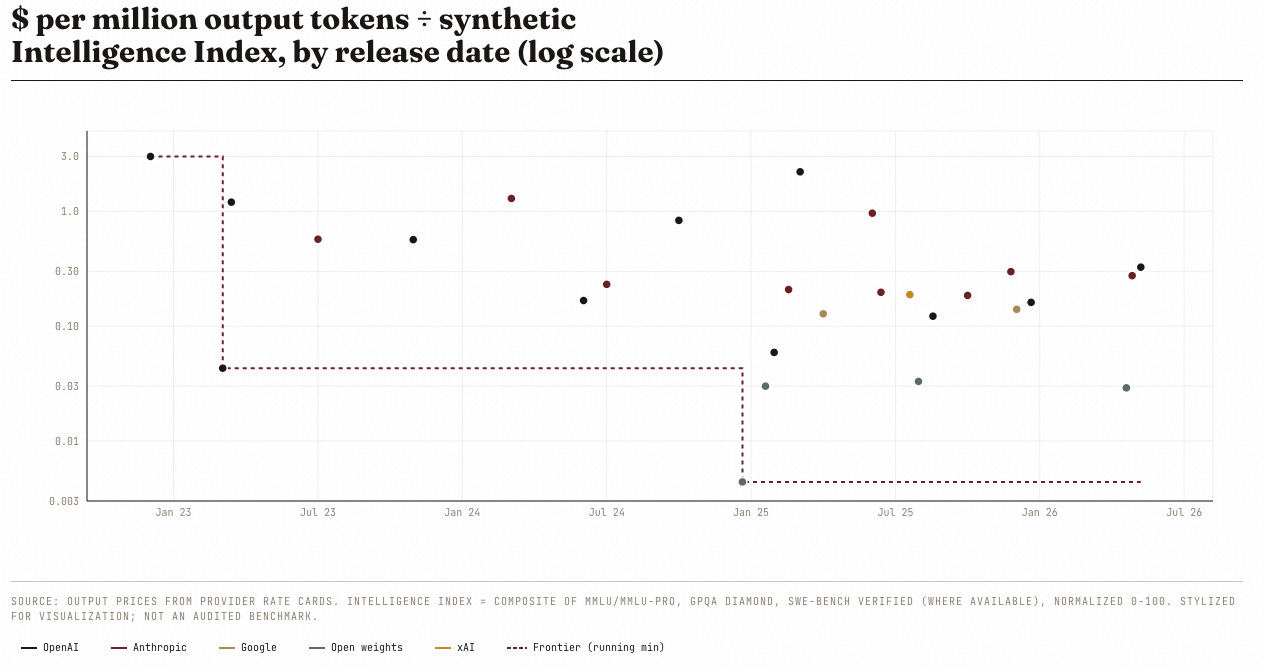
Three things worth reading off the scatter:
GPT-4.5 at 2.21 is the worst deal of the modern era and the only model deprecated as too expensive to keep alive.
Anthropic's flagships consistently sit at the top of the cloud. They price for the claimed quality premium.
The frontier hasn't fallen since DeepSeek V3. For sixteen months, "cheapest intelligence available" has been static.
Token demand surging
The cost of intelligence alone is not going to tell us enough, because we also need to understand just “how much intelligence do we need”. The moment you look at this, you’ll see a different story.
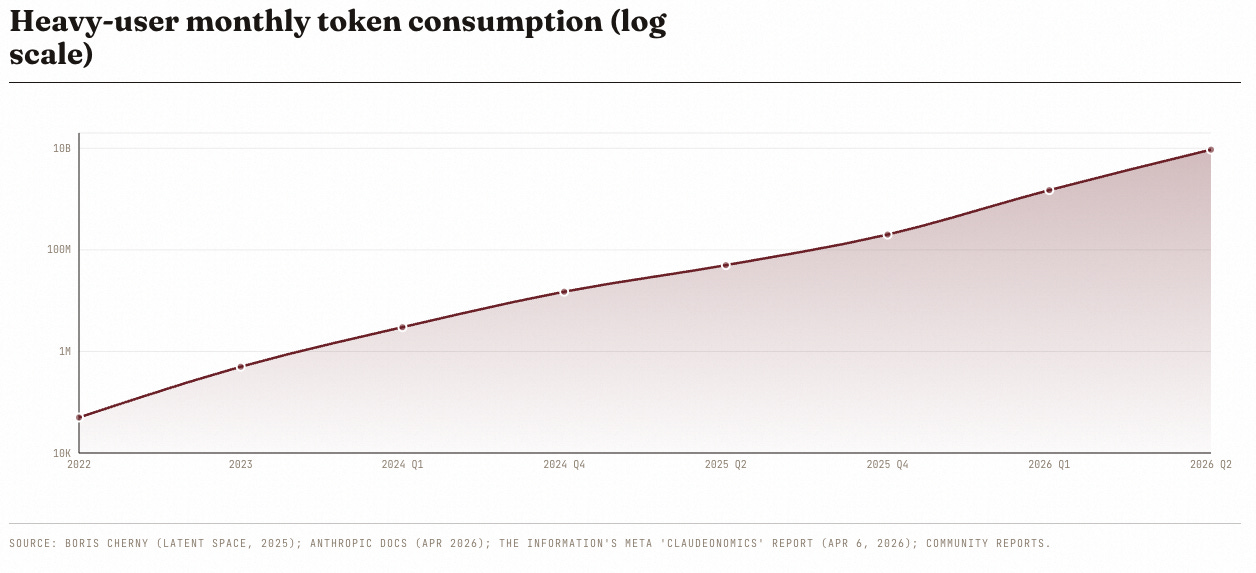
While the unit price has fallen, the typical heavy-user monthly token consumption has scaled faster. The chat user of 2022 burned ten to a hundred thousand tokens a month. The “Token Legend” of Meta’s 2026 leaderboard burned 9.4 billion a day.
Jevons Paradox is alive and well and demand is surging like there’s no tomorrow.
When you try to look at the two phenomena at once, you’ll see that in action:
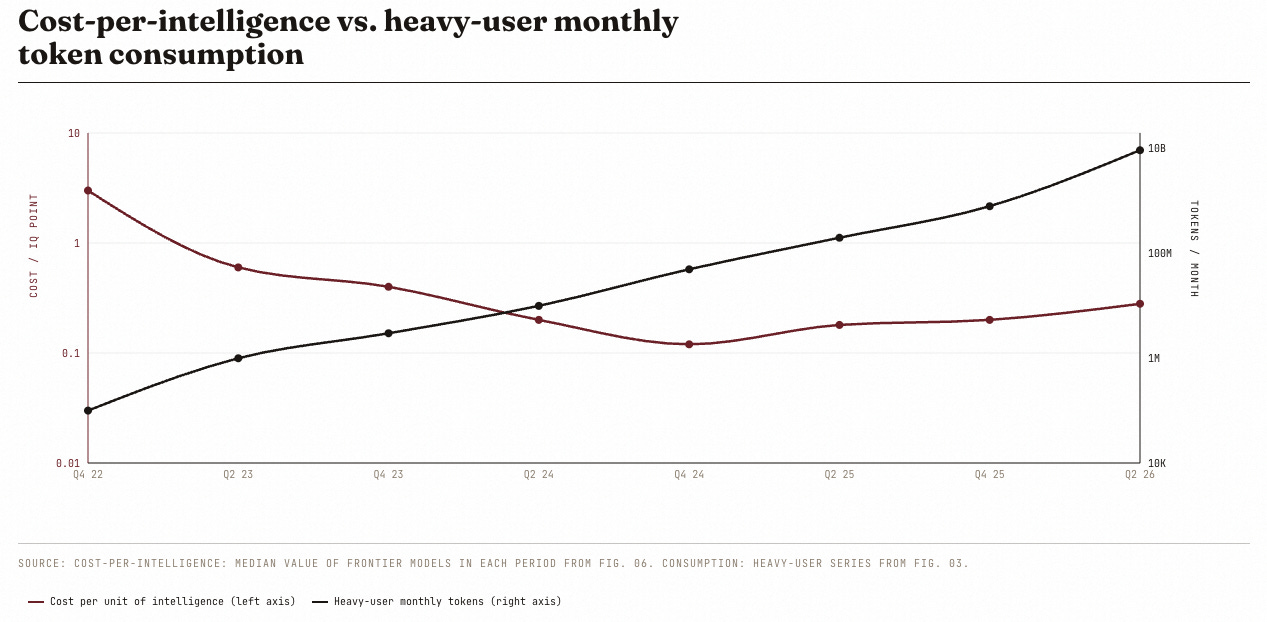
Between Q4 2022 and Q2 2026, cost-per-intelligence fell from 3.00 to about 0.28, roughly a 10× drop. Over the same period, heavy-user monthly token consumption rose from 100,000 to 9.4 billion, a 94,000× increase. Consumption is outrunning cost-deflation by four orders of magnitude.
So the marginal cost of intelligence may be declining (10x drop is still significant) but demand growth kills the gains. Let’s look at API-equivalent costs versus token demand and it becomes clear what we’re all feeling: AI is getting more expensive.
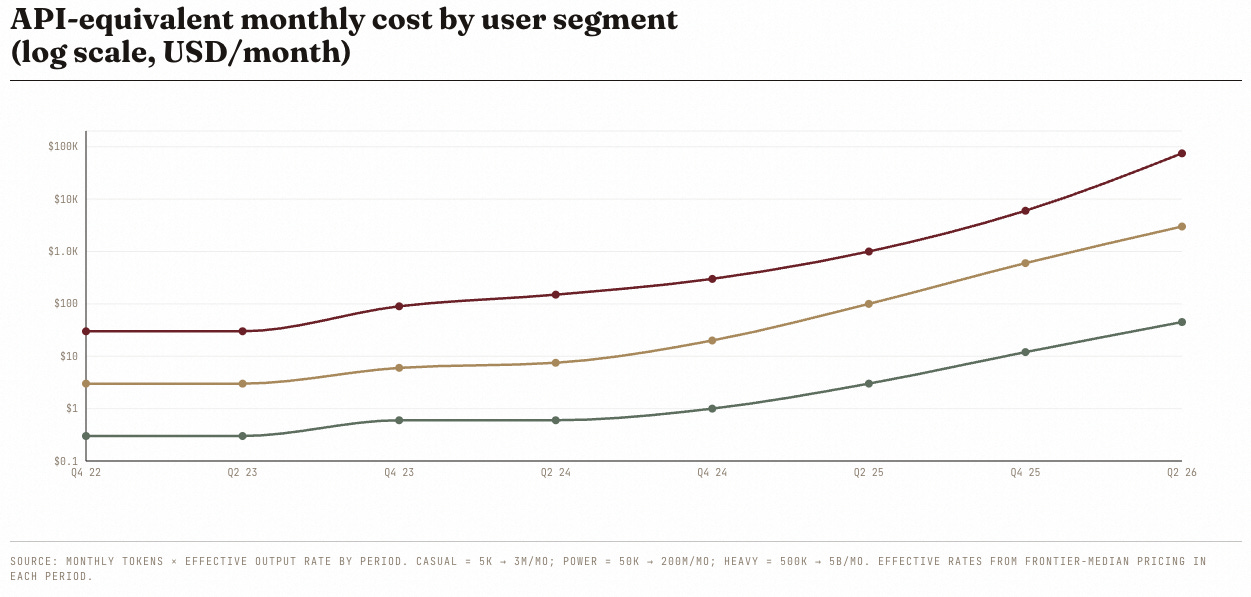
The casual user’s API-equivalent bill went from thirty cents a month to forty-five dollars, a 150× rise. The power user’s, from three dollars to three thousand. The heavy user’s, from thirty dollars to seventy-five thousand. In every segment, real cost has risen despite per-token cost falling.
This is Jevons Paradox in its purest form. The only thing standing between heavy users and a five-figure monthly invoice is an implicit subscription subsidy, and that subsidy is being progressively wound down.
Claude Max, ChatGPT Pro, Kimi Code, Minimax Token Plan and all the other subscription products are pitted against this.
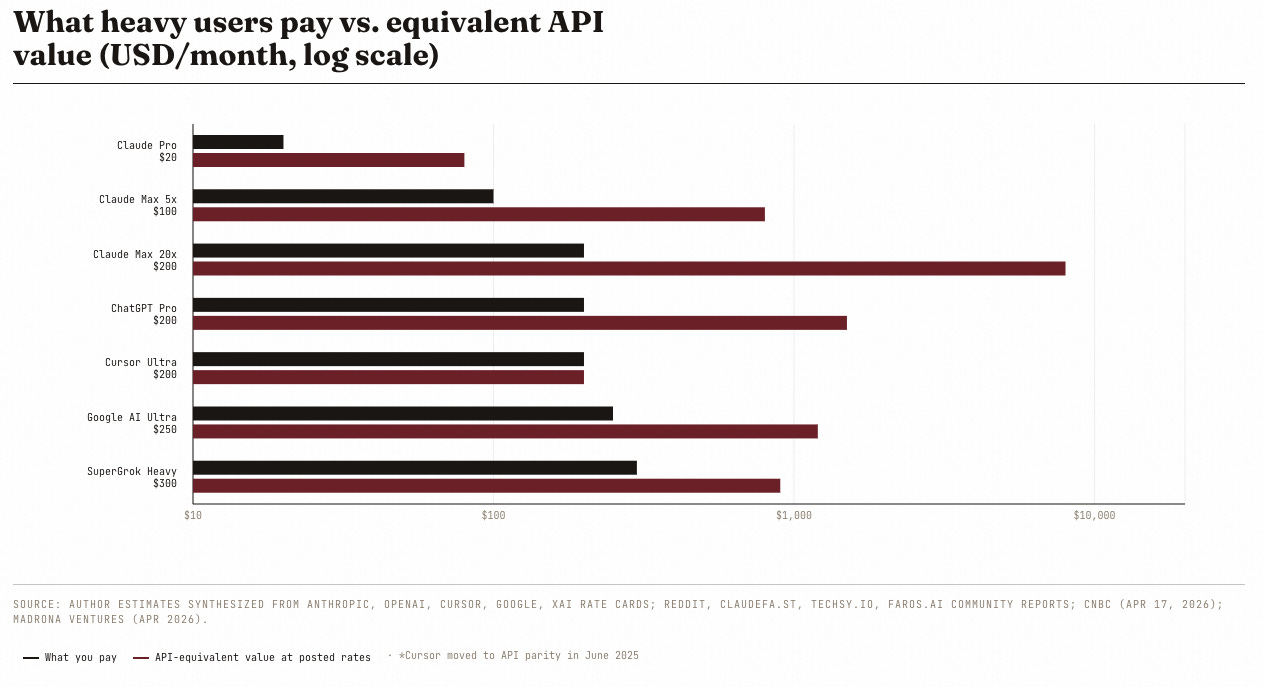
When you’re maxxing out on Claude Max you’re not using $200 worth of tokens, but $10k. The other $9.8k is paid for by Big AI investors who believe this problem will get an economically feasible solution soon enough so the subsidies can end and profits will soar.
Much like what happened with Uber, which started out as vastly cheaper alternative to taxis, only to start extracting loads of cash from their customers once they dominated the market.

Big AI knows this. Nick Turley, head of ChatGPT on the BG2 podcast said:
"It's possible that in the current era, having an unlimited plan is like having an unlimited electricity plan. It just doesn't make sense."
Amol Avasare of Anthropic said something similar:
"Engagement per subscriber is way up. Usage has changed a lot and our current plans weren't built for this."
Boris Cherny linked this with Anthropic’s widely hated ban on third-party tool access with Claude subs reinforcing that the plans "weren't built for the usage patterns of these third-party tools."
What tokens actually buy?
Anthropic, Microsoft and all the other big players claim that tokens are (or will be) buying knowledge work. Messy, valuable, expensive knowledge work.
This is a bit more nuanced argument than “intelligence too cheap to meter”. An AI agent that is capable of the exact same value output at $100/hour than a human counterpart will still be a better hire, because no HR, no rights, no sick leave, no holidays just consistent output.
But can these agents actually do stuff and what’s the cost of that? For individual tasks, it would seem that agents are getting better at doing things and over time doing such things get cheaper too.
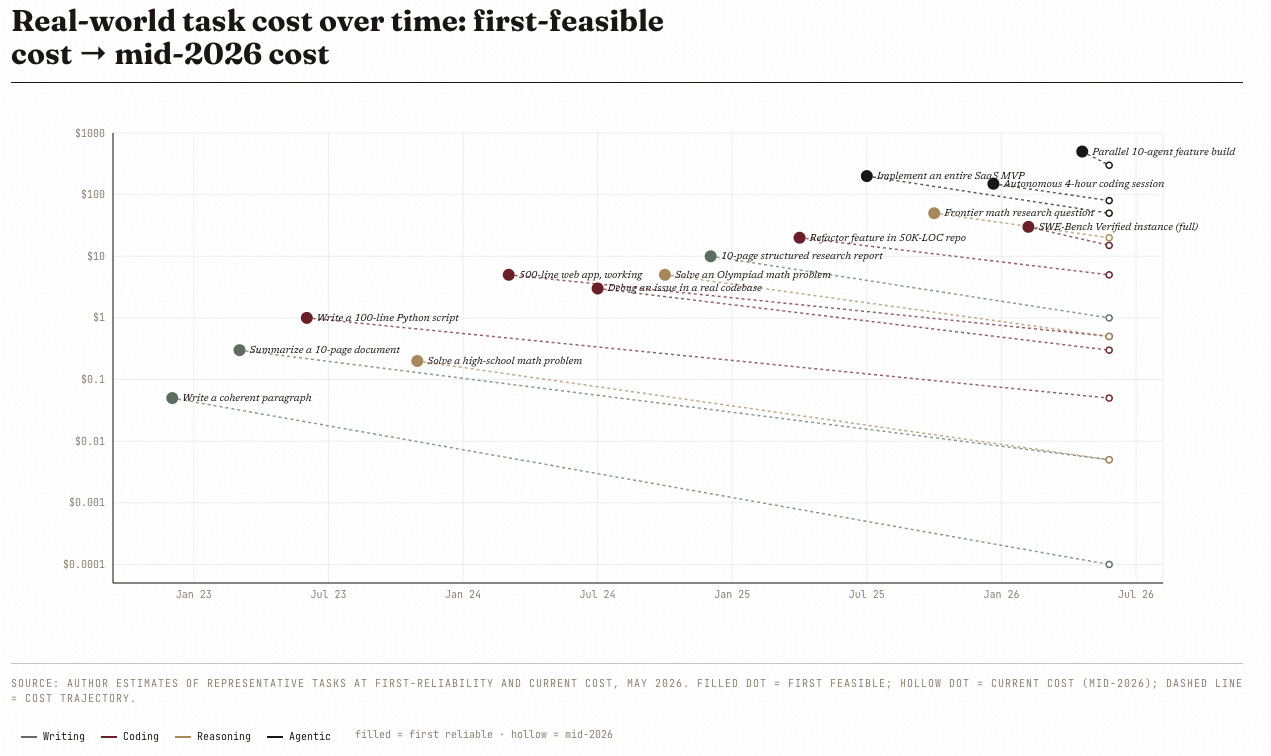
Two readings co-exist.
The optimist’s: tasks that were impossible at any price in November 2022 now cost between fractions of a cent (paragraph writing) and a few hundred dollars (autonomous multi-hour agent work). The capability ladder is real.
The pessimist’s: each new rung is more expensive than the last to reach the threshold, and the heaviest tasks still cost hundreds of dollars to attempt with no guarantee of completion. The question for an architect is whether the new rung is worth the climb, or whether the previous rung, at a hundredth of the price, would have done the job.
Following the pessimist’s take, once an architect finds the answer to this question, they would need to engineer a harness that routes the right agents to the right rung at given situations, effectively putting a harness on the agent. This echoes Mitchell Hashimoto’s definition of agents: Agent = Model + Harness.
What the data says
If consumption growth swamped price decline, and the subsidy is structurally unsustainable, the natural follow-up question is whether all that consumption is buying anything of value.
The answer, from the most rigorous available data, is: some of it, for some people, sometimes.
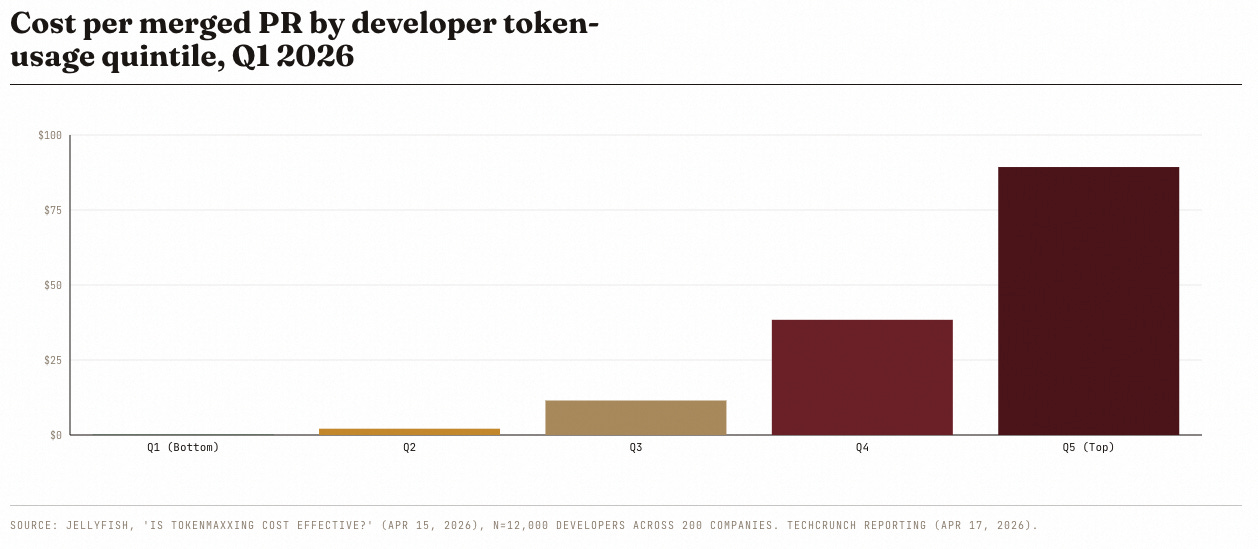
Jellyfish looked at the data of thousands of engineers and a few weeks ago came to the conclusion that agentic engineering for most people means one thing:
“They achieved two times the throughput at ten times the cost of tokens.”
This echoes with what others are seeing as well. Andrej Karpathy said in October 2025 that
“There’s some over-prediction going on in the industry. In my mind, this is more accurately described as the decade of agents.”
Gil Luria and D.A. Davidson went as far to say this is not surprising at all and it’s all Big AI’s fault.
“You get the behavior that you create the incentive for. So if you tell people they'll succeed if they use a resource more, of course they'll use it more.”
That is the textbook Goodhart's Law diagnosis. Inside the reporting on tokenmaxxing itself, the metric is already shifting.
Salesforce has installed circuit breakers on runaway agents and migrated its dashboard from "who spent the most" to "whose tokens cost the most relative to output."
Angie Jones, formerly Block's VP of engineering for AI tools, expects the industry to pivot to efficient token usage rather than volume.
The leaderboard era is shorter than it looked. Meta even took it down after 48 hours.
Two Token Playbooks
Tokenmaxxing works for some people in some cases, sometimes.
Unpacking this will give us clues on where to focus. The agent decade seems to be real, but the timeline is a lot longer than marketing would suggest. In the meantime, consumption growth dominates price decline, which means that tokenmaxxing as an individual metric is broken.
When looking under the hood you can find the dirty nuances. Hashimoto’s definition that an Agent = Model + Harness seems to be the most robust one for now.
The good news is harnesses can be built. The bad news is they seem to be unique to how you work: Huntley’s Ralph loops or Cherny’s parallel-PR workflow are proof of incredible meta-cognition about their own work, which is a rare skill: frame and untangle the way you work well so you can rebuild it from scratch with a proper harness.
So how do you win?
Maybe it’s worth separating individual power users from builders.
Playbook for Power Users
Capture the subsidy while it lasts.
Claude Max 20x at $200/mo delivers $2k–$10k of API value today. Use it; don’t build production-critical workflows on the assumption that implicit token price stays under $1/M.
Build harnesses before scaling agents.
Every dollar in harness engineering returns more than a dollar in tokens. If your cost-per-completed-task isn’t falling while spend grows, you’re tokenmaxxing in the bad sense.
Route by model, aggressively.
Opus-plan / Sonnet-execute / Opus-review, plus Haiku for routine work, plus Kimi K2.6 or DeepSeek V3.2 for bulk. Cut spend 3–5× at constant quality.
Track “tokens to first useful output.”
Not gross tokens. This is the metric Salesforce has migrated to and Angie Jones predicts will win.
Playbook for Builders
Assume customer subscription costs double in 12–18 months.
Price your product against API rate cards, not the current subscription subsidy. Don’t sell against $200 Claude Max.
Build in model portability.
The Kimi K2.6 / DeepSeek V3.2 cost arbitrage versus Claude is a real 10× lever and it grows as open-weight models close the SWE-Bench gap. An LLMRouter abstraction at the architecture layer.
Instrument for the Goodhart trap from day one.
If customer token usage rises but task-completion rate doesn’t, log both and make per-task cost the headline metric.
Watch the “decade of agents” inflection.
Karpathy’s blockers (continual learning, computer-use reliability, multimodality) are the tripwires. When two of three break, the subsidy story becomes moot.
Finishing thoughts
Tokens are getting cheaper but demand is increasing faster than that. Agents require orders of magnitude more tokens to actually generate value. Without custom built harnesses, agentic work becomes a net loss, but with properly built harnesses you can capture meaningful increase in output.
The next few years will make you feel like AI is getting more expensive all of a sudden, while some winners will emerge with great, purpose built harnesses that can reduce token waste and generate positive ROI.
Predictions of this happening in the next 1-2 years are not supported by data at all. To prove my point I will give you a walkthrough on different token use scenarios of me using Alfred (my heavily modded Openclaw agent).
>"It showed that a top employee averaged 281 billion tokens per month (~$1.4million in API costs). To compare, Alfred, which is running as my personal chief of staff averages around 2-4 billion tokens per month."
Using the same cost Meta referenced, you're spending $10-20k per month on your agent. I assume that's not the case and you have some optimizations to bring that number way down?